

MNIST Express - 3/8 - k-NN n'est pas naïf : géométrie et distances
- 27 févr.
- 4 min de lecture
Dernière mise à jour : 22 mars
Lien vers l'appli : https://mnist-express.streamlit.app/
Lien vers le repo du projet : https://github.com/vohorgeez/MNIST-Express
Dans l'article précédent, on a vu comment NumPy transforme des images en vecteurs. 28x28 pixels deviennent 784 nombres.
Aujourd'hui, on répond à la vraie question :
Comment un modèle peut-il reconnaître un chiffre... juste en comparant des vecteurs ?
Spoiler : il fait de la géométrie.
MNIST, mais vu comme un espace
Petit rappel du précédent article : chaque image MNIST est une grille 28x28 pixels qui ressemble à ça :

Une fois aplatie, ce merveilleux "3" ne sera plus une image, mais un point dans un espace à 784 dimensions.
Oui, oui, 784 dimensions. C'est absolument inconcevable pour un cerveau humain de se représenter l'espace au-delà de trois dimensions. Là on va conceptualiser un espace qui en contient 784 DANS LE PLUS GRAND DES CALMES.
Chaque chiffre devient donc un point dans cet espace immense. Classifier un nouveau dessin revient à poser une question simple :
A quels points déjà connus ressemble-t-il le plus ?
k-NN : c'est peut-être pas le plus intelligent, mais c'est l'algorithme le plus honnête du monde

k-NN signifie k-Nearest Neighbors.
Les k plus proches voisins dans la langue de Molière.
Traduction :
Ce point que je ne connais pas doit forcément être similaire aux k points les plus proches de lui : viens, on regarde qui sont les k points les plus proches, et on prends la majorité.
C'est aussi simplet que ça. Pas besoin d'entraînement complexe. Même pas besoin d'introduire des poids ou autre maraboutage cryptique. On se contente de mesurer la distance, de trier, de voter et basta.
On dit qu'il est "naïf", parce qu'en l'état, il ne "comprend" rien. En réalité, il repose entièrement sur une hypothèse géométrique très forte :
Les objets similaires sont proches dans l'espace.
Si cette hypothèse est vraie, k-NN est redoutable malgré sa simplicité.
Un exemple d'application, avec une vidéo en français :
La distance euclidienne : Pythagore version 784D
La distance la plus utilisée est la distance euclidienne. C'est la distance "à vol d'oiseau", la ligne droite du point 1 au point 2, quoi.
C'est le moment où je vais vous rappeler les douces années de collège avec Pythagore. Vous vous souvenez comment on calcule l'hypoténuse C du triangle rectangle, sachant la longueur des deux autres côtés A et B ? Allez :

Maintenant imaginez que le côté A soit une mesure de l'axe des abscisses, le côté B une mesure d'axe des ordonnées dans un repère orthonormé en deux dimensions, et C devient une distance à calculer :

Voilà comment on calcule la distance euclidienne en 2 dimensions (notez qu'il y a 2 carrés sous la racine, un par dimension). Bien, comment fait-on en 784D ?
Bah, pareil... mais avec 784 termes (ou carrés) au lieu de 2.
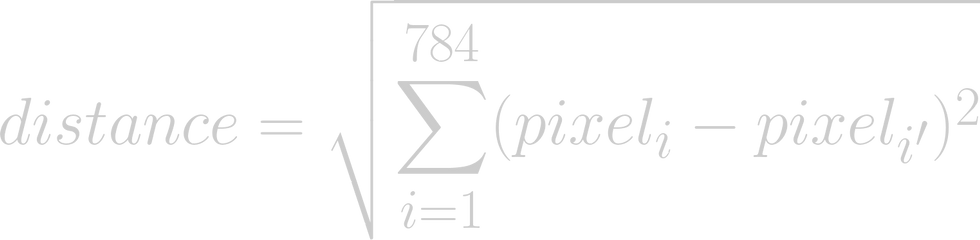
Chaque pixel "contribue" à la distance.
Un pixel très différent = contribution forte.
Beaucoup de petits écarts = distance globale plus grande.
Autrement dit :
Deux chiffres sont proches si leurs pixels sont proches.
C'est brut, mathématique, froid, bref, c'est indiscutable.
Intuition géométrique
Imaginons un espace en 2 dimensions avec des points bleus et rouges. Un nouveau point arrive. Il regarde ses voisins les plus proches. Si la majorité est rouge -> il devient rouge.

En 784 dimensions, c'est exactement pareil. C'est juste impossible à visualiser. C'est là que les mathématiques sont un outil d'abstraction génial : la visualisation disparaît, mais l'abstraction mathématico-géométrique demeure...
Le Fléau de la dimension : limite du modèle
Et maintenant, le moment où ça se complique.
Reprenons la formule de la distance euclidienne. A votre avis, que se passe-t-il si on augmente le nombre de termes dans la somme sous la racine (c.à.d, quand on augmente le nombre de dimensions) ? La distance grandit de manière artificielle... En clair, plus on augmente le nombre de dimensions, et plus :
les points "s'éloignent" tous les uns des autres ;
les distances deviennent de moins en moins discriminantes ;
tout tend à devenir équidistant.
C'est ce qu'on appelle le Fléau de la dimension.
Dans un espace très grand :
le volume explose
les données deviennent rares
la notion de "proche" devient floue
En pratique, deux images peuvent sembler "presque aussi loin" l'une de l'autre en 784 dimensions, même si elles représentent des chiffres différents.
C'est pour ça que :
k-NN devient lent
les distances deviennent moins pertinentes
la réduction de dimension (PCA, LDA) devient stratégique.
Pourquoi k-NN reste puissant malgré tout
Malgré la malédiction dimensionnelle, k-NN fonctionne bien sur MNIST, car les chiffres sont centrés, normalisés, bien structurés et relativement "propres". La géométrie naturelle des données aide énormément.
k-NN ne crée pas de frontière complexe. Il épouse simplement la forme du nuage de points. C'est une classification par voisinage local.
Ce que fait réellement MNIST Express
Dans le projet :
Une image est transformée en vecteur.
Elle est éventuellement réduite en dimension (PCA).
Elle est comparée à toutes les images d'entraînement.
Les k plus proches votent.
Le label majoritaire est retourné.
Ni plus ni moins. Et pourtant, et c'est ça qui est magique, on obtient facilement plus de 95% d'accuracy.
Pas besoin de deep learning, pas besoin de GPU, pas besoin de magie noire : juste la puissance de la géométrie. 😎
La naïveté relative de k-NN
k-NN n'est finalement pas si naïf. Il repose sur une idée simple, mais profonde :
La similarité est une question de distance.
Mais cette idée à des limites :
trop de dimensions et les distances deviennent peu informatives ;
trop de données et le coût computationnel devient élevé.
C'est un algorithme honnête qui ne triche pas : il ne fait que comparer. Et pour ce projet, on ne demande pas mieux !


Commentaires